Turning a Website into an API
Building a FastAPI service that scrapes GitHub Trending data and exposes it as a developer-friendly API.
Heya fellows,
The amount of interesting data which can be found on websites is increasing from day to day. These data are scraped by search engines to improve search results, they're collected to create machine learning models or just processed and other services/apps are recreated from them.
The latter can be achieved by scraping data and then exposing them as RESTful API to other developers so they can build their services/apps around it.

Non-coding solutions like APIFY or scrapingbot emerged in recent years to simplify this process. Data are scraped from popular (e-commerce) platforms and they are served over an API as developer-friendly JSON. But these apply only to big, popular platforms and cannot be applied to every website.
So I thought it would be nice to build such a web scraping API to learn more about web scraping and web development. I found this unofficial Github trending API written in Javascript. It is not available anymore. So I planned to rewrite this API in Python and make it accessible.
Contents
Python has great 3rd party packages for web scraping like Scrapy, BeautifulSoup or Requests-HTML to name just a few. I will use BeautifulSoup and the aiohttp package to perform asynchronous requests via the HTTP protocol. FastAPI has a nice built-in documentation and makes extensive use of pydantic which makes data parsing and validation pretty intuitive.
1. Scraping Repository Data
At first I wrote some Python code to scrape the desired data. I saved a sample of the trending repositories HTML to avoid sending dozens of requests to Github. I use HTTPie as HTTP client to perform requests via the terminal.
$ http -b https://github.com/trending > repositories.html
$ wc repositories.htmlThe HTML file has a size of 695 KB. The wordcount shows that ~710.000 characters are distributed over ~6000 lines. The file contains 25 repositories waiting for me to be scraped 🙂. Each repository is enclosed by an article-tag.
I opened the file from Python and tried to scrape the HTML document.
import bs4
with open('repositories.html', 'r') as f:
articles_html = f.read()
soup = bs4.BeautifulSoup(articles_html, "lxml")
articles = soup.find_all("article", class_="Box-row")
print(f'number of articles: {len(articles)}')After trying to scrape different repository data I realized that BeautifulSoup does not find all articles reliably. Some research revealed that others observed this as well. So I wrote a filter function as a workaround. This function filters all HTML out which is enclosed by the article-tags.
def filter_articles(raw_html: str) -> str:
raw_html = raw_html.split("\n")
# count num of article tags (varies from 0 to 50):
article_tags_count = 0
tag = "article"
for line in raw_html:
if tag in line:
article_tags_count += 1
# copy HTML enclosed by first and last article-tag:
articles_arrays, is_article = [], False
for line in raw_html:
if tag in line:
article_tags_count -= 1
is_article = True
if is_article:
articles_arrays.append(line)
if not article_tags_count:
is_article = False
return "".join(articles_arrays)The now created ‘bs4.element.ResultSet’ instances have always the expected length. Next we have to access the data within the soup and store them into a dictionary. The tags containing the desired data can be accessed using soups find-method or by going along the DOM tree via dot-notation. The latter is preferred performance-wise! Each repository is described by 12 properties. The function became quite lengthy, so I’ll show only a part of the function (scraping 4 properties).
def scraping_repositories(
matches: bs4.element.ResultSet,
since: str
) -> typing.List[typing.Dict]:
trending_repositories = []
for rank, match in enumerate(matches):
# relative url
rel_url = match.h1.a["href"]
# name of repo
repository_name = rel_url.split("/")[-1]
# author (username):
username = rel_url.split("/")[-2]
# language and color
progr_language = match.find("span", itemprop="programmingLanguage")
language = progr_language.get_text(strip=True)
lang_color_tag = match.find("span", class_="repo-language-color")
lang_color = lang_color_tag["style"].split()[-1]
else:
lang_color, language = None, None
repositories = {
"rank": rank + 1,
"username": username,
"repositoryName": repository_name,
"language": language,
"languageColor": lang_color,
}
trending_repositories.append(repositories)
return trending_repositoriesFor data about trending developers I have written a another scraping function. Ok, now that we can scrape the HTML, users have to be able to retrieve the data via a GET request.
2. FastAPI
FastAPI makes building APIs a breeze. Here’s an example:
import fastapi
import uvicorn
app = fastapi.FastAPI()
@app.get("/")
def index(myArg: str = None):
return {"data": myArg}
if __name__ == "__main__":
uvicorn.run(app, port=8000, host="0.0.0.0")The path operation decorator @app.get("/") handles requests that go to the "/" route using a GET operation. The path operation function index() let’s us handle query parameters. The code snippet contains an optional query parameter.
$ http -b http://0.0.0.0:8000/?myArg=hello
{
"data": "hello"
}We will create endpoints similar to the endpoints on Github. The programming language can be specified by a path parameter whereas the date range and the spoken language can be specified by an optional query parameter. Here’s an example:
/c++?since=weekly&spoken_lang=de
FastAPI lets us define a set of allowed data which can be selected by the user. We have to create classes which contain the allowed properties and inherit from the Enum class.
class AllowedDateRanges(str, Enum):
daily = "daily"
weekly = "weekly"
monthly = "monthly"When opening FastAPIs documentation we will see that only 3 options for the date range will be available:
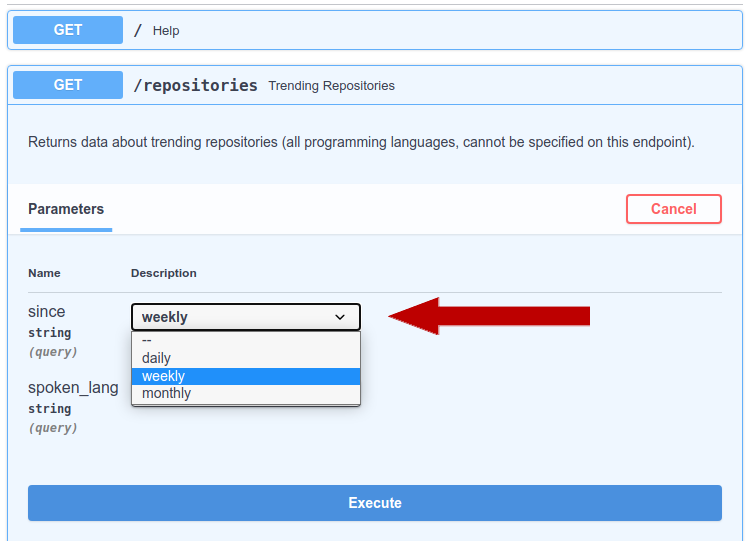
The code for the routing will be written within a main.py file. The path operation function accepts only allowed path parameters (programming languages) and optional query parameters (date ranges and spoken languages).
@app.get("/repositories/{prog_lang}")
async def trending_repositories_by_progr_language(
since: AllowedDateRanges = None,
):
return {"dateRange": since}Ok, now I know how the endpoints should look like, but before the user can choose between different options at all, I have to make make the web scraping dynamic by requesting the desired HTML from Github instead of just opening a local HTML copy. Pythons well-known requests module does the job. The goal is to let the user select between different parameters. The parameters of the request are redirected as payload to Github to receive the desired HTML.
import requests
payload = {
'since': 'daily',
'spoken_language_code': 'en',
}
prog_lang = 'c++'
resp = requests.get(f"https://github.com/trending/{prog_lang}", params=payload)
raw_html = resp.textNext, I will put the 3 parts together: the user can request data of trending repositories. The shown path operation function gives us the ability to specify the search for trending repositories (by programming language, period of time and spoken language. These arguments are redirected as payload to request the desired HTML which is at last scraped and returned as JSON.
@app.get("/repositories/{prog_lang}")
def trending_repositories_by_progr_language(
prog_lang: AllowedProgrammingLanguages,
since: AllowedDateRanges = None,
spoken_lang: AllowedSpokenLanguages = None,
):
payload = {"since": "daily"}
if since:
payload["since"] = since._value_
if spoken_lang:
payload["spoken_lang"] = spoken_lang._value_
resp = requests.get(f"https://github.com/trending/{prog_lang}", params=payload)
raw_html = resp.text
articles_html = filter_articles(raw_html)
soup = make_soup(articles_html)
return scraping_repositories(soup, since=payload["since"])But how does the app perform? Professional tools like ApacheBench or k6 are commonly used to perform load testing, but in this case I wrote a small asynchronous script to bomb the application with requests. Comparing the performance of sync or async web apps without using async requests would be nonsense. I’ll call it requests_benchmark.py and place it within the tests/ folder. Be aware that this is a rough comparison, I just want to illustrate the difference between synchronous and asynchronous code.
import asyncio
import time
import aiohttp
URL = "http://127.0.0.1:8000/repositories/c++?since=weekly"
url_list = list([URL] * 50)
async def fetch(session, url):
"""requesting a url asynchronously"""
async with session.get(url) as response:
return await response.json()
async def fetch_all(urls, loop):
"""performaning multiple requests asynchronously"""
async with aiohttp.ClientSession(loop=loop) as session:
results = await asyncio.gather(
*[fetch(session, url) for url in urls],
return_exceptions=True,
)
return results
if __name__ == "__main__":
t1_start = time.perf_counter()
event_loop = asyncio.get_event_loop()
urls_duplicates = url_list
htmls = event_loop.run_until_complete(
fetch_all(urls_duplicates, event_loop),
)
t1_stop = time.perf_counter()
print("elapsed:", t1_stop - t1_start)I executed the script 3 times making 20 requests on each execution. Ok now lets replace the synchronous requests library by the asynchronous aiohttp library. Furthermore, we add the async/await keywords on the right positions. Our final code will look like this:
@app.get("/repositories/{prog_lang}")
async def trending_repositories_by_progr_language(
prog_lang: AllowedProgrammingLanguages,
since: AllowedDateRanges = None,
spoken_language_code: AllowedSpokenLanguages = None,
):
payload = {"since": "daily"}
if since:
payload["since"] = since.value
if spoken_language_code:
payload["spoken_language_code"] = spoken_language_code.value
url = f"https://github.com/trending/{prog_lang}"
sem = asyncio.Semaphore()
async with sem:
raw_html = await get_request(url, compress=True, params=payload)
if not isinstance(raw_html, str):
return "Unable to connect to Github"
articles_html = filter_articles(raw_html)
soup = make_soup(articles_html)
return scraping_repositories(soup, since=payload["since"])Again three measurements were done using the requests_benchmark.py script. The average of the measurements were calculated and the requests per second of synchronous and asynchronous code are compared as a barchart. The asynchronous code performs roughly twice as good.

Three more routes will be written to cover all trending repositories and developers. Our last task then is to deploy our application.
3. Deployment to Heroku
We’ll use Heroku which is an excellent Platform as a service (PaaS) cloud provider. To deploy our API to heroku we need a heroku.yml file…
build:
docker:
web: Dockerfile…and a Dockerfile. For the docker image we use the lightweight linux-distribution alpine. This results in a 80Mb sized image which is built when executing the docker build -t gh-trending-api . command. The lxml package we use for the webscraping requires libxml, a C-library. Therefore we need to compile C-code and thus building the docker container can take up to several minutes.
FROM python:3.9.2-alpine3.13
LABEL maintainer="Niklas Tiede <niklastiede2@gmail.com>"
WORKDIR /github-trending-api
COPY ./requirements-prod.txt .
RUN apk add --update --no-cache --virtual .build-deps \
g++ \
libxml2 \
libxml2-dev && \
apk add libxslt-dev && \
pip install --no-cache-dir -r requirements-prod.txt && \
apk del .build-deps
COPY ./app ./app
CMD uvicorn app.main:app --host 0.0.0.0 --port=${PORT:-5000}Then we have to publish the port we defined in the CMD instruction of the Dockerfile (port 5000) to the outside world. We have to map the containers port to a port on the docker host when running the container:
$ docker run -p 5000:5000 gh-trending-api:latestNext we automate the deployment process using Github Actions. We create a release_and_deploy.yaml file within a .github/workflow/ folder and place the following code. It contains the Github action “Deploy to Heroku” which will do the deployment for us.
name: GH Release, Publishing to Docker and Deployment to Heroku
on:
push:
tags:
- 'v*.*.*'
jobs:
test:
runs-on: ubuntu-latest
steps:
heroku-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@master
- name: Deploy on Heroku
uses: akhileshns/heroku-deploy@v3.12.12
with:
heroku_api_key: ${{secrets.HEROKU_API_KEY}}
heroku_app_name: "gh-trending-api"
heroku_email: "niklastiede2@gmail.com"We copy the HEROKU_API_KEY from Heroku’s account settings and save this as a secret in our Github repository so our Github action can access it. Now each time we push a tag of our project into the remote repository, this workflow kicks in. It pushes the project to Heroku which will build and run the docker container of our application. The URL of our app can be reached at https://gh-trending-api.herokuapp.com/
Aaaand, thats it! We deployed a nice-looking API 😙
4. Conclusion and Future Directions
Here is the full source code of the project: Github Trending API
It took me 3 days to build this API. Another 2 days were needed to learn how to use Pythons async/await syntax. But using asynchronous code increased the performance not as much as I expected it to be. The scraping itself seems to be the bottleneck of the API, it’s kinda CPU intensive. I also found out that beautifulsoups performance is not that good. Using the .find method is slower than going down the DOM tree by hand.
If it turns out that this API would have a higher traffic in the future it could be interesting to implement a caching mechanism. Github updates the rankings of trending repositories only a few times per day so it would be more efficient to cache the most often used rankings in memory until Github updates it. This approach avoids repetitive requests and scraping the same data. It would be very interesting to implement a Redis database for this job.
Ok guys, I hope you found something interesting, thanks for your attention and have a nice day!